

هرچه با ChatGPT بیادبانهتر برخورد کنید، پاسخهای دقیقتری میدهد
اخلاقیات مربوط به تعامل با چتباتهای هوش مصنوعی و خطرات احتمالی آن، مانند اطلاعات گمراهکننده یا تحریک به اقدامات خشونتآمیز، همواره مورد بحث بوده است. با این حال، به نظر میرسد نوع زبانی که برای رفتار چتباتها به کار میبریم، بر کیفیت پاسخها و بهبود پاسخهای AI نیز تاثیرگذار است.
عصر ایران: اخلاقیات مربوط به تعامل با چتباتهای هوش مصنوعی و خطرات احتمالی آن، مانند اطلاعات گمراهکننده یا تحریک به اقدامات خشونتآمیز، همواره مورد بحث بوده است. با این حال، به نظر میرسد نوع زبانی که برای رفتار چتباتها به کار میبریم، بر کیفیت پاسخها و بهبود پاسخهای AI نیز تاثیرگذار است.
یک تحقیق جدید نشان میدهد که دقت چت جیپیتی میتواند با بیادبی در تعامل با آن، افزایش یابد. این یافتهها دیدگاههای رایج درباره رفتار با چتباتها را به چالش میکشد.
اخلاقیات مربوط به تعامل با چتباتهای هوش مصنوعی و خطرات احتمالی آن، مانند اطلاعات گمراهکننده یا تحریک به اقدامات خشونتآمیز، همواره مورد بحث بوده است. با این حال، به نظر میرسد نوع زبانی که برای رفتار چتباتها به کار میبریم، بر کیفیت پاسخها و بهبود پاسخهای AI نیز تاثیرگذار است.
نتایج غیرمنتظره یک تحقیق جدید
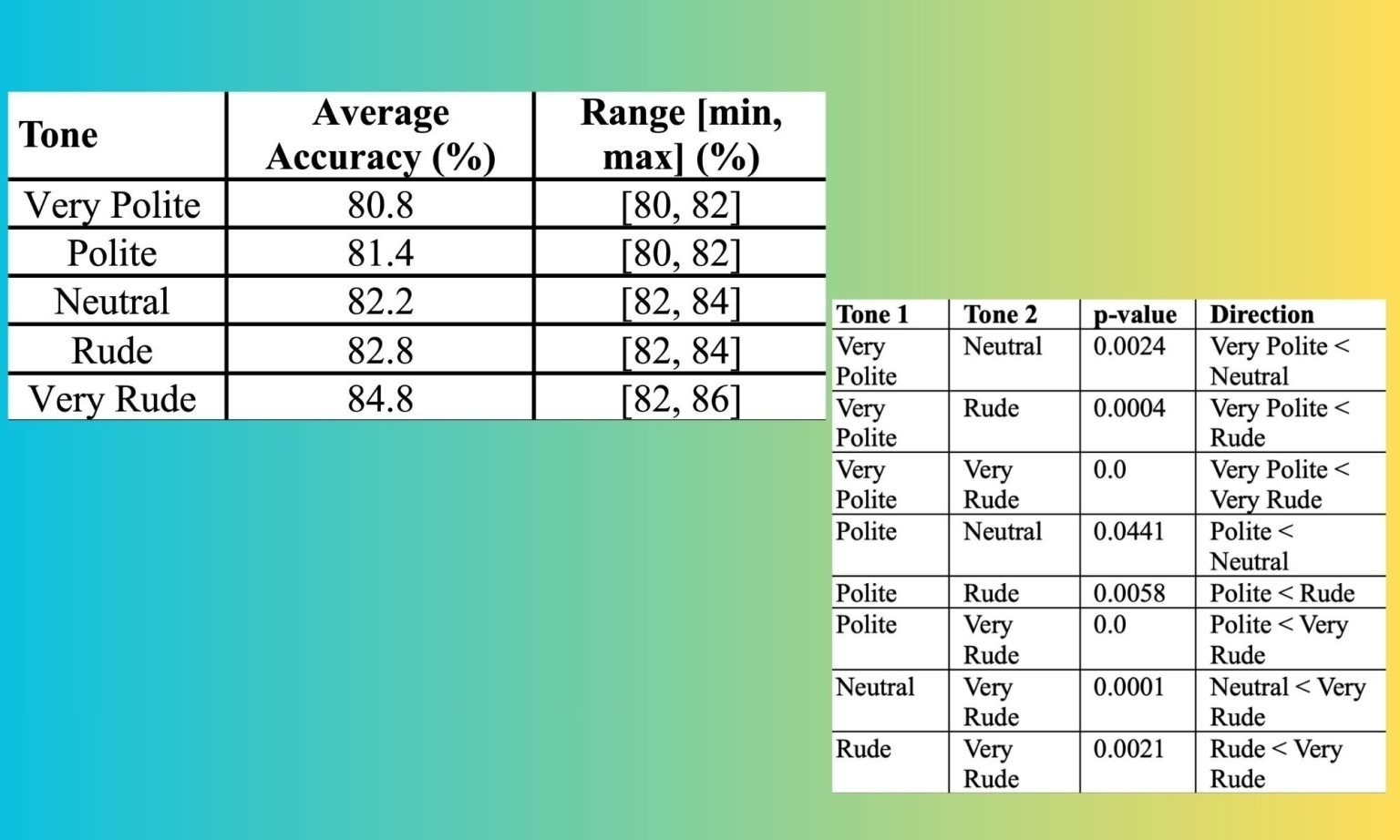
بر اساس یک مقاله تحقیقاتی که توسط متخصصان دانشگاه ایالت پنسیلوانیا منتشر شده، وقتی از ChatGPT سوالات یکسانی با لحنهای متفاوت پرسیده شد، سوالات بیادبانه “به طور مداوم عملکرد بهتری” نسبت به سوالات مودبانه داشتند. در یک قالب آزمون چندگزینهای، دقت پاسخهای ارائهشده توسط ChatGPT با سوالات مودبانه ۸۰.۸ درصد بود، در حالی که همین سوالات با لحنی بسیار بیادبانه، دقت پاسخها را به ۸۴.۸ درصد افزایش داد.
تیم تحقیقاتی لحن سوالات را در پنج سطح طبقهبندی کرد: خیلی مودبانه، مودبانه، خنثی، بیادبانه و خیلی بیادبانه. سوالات خنثی بدون استفاده از کلمات مودبانه مانند “لطفاً” و عبارتهای آمرانه یا تحقیرآمیز بودند.
ابهامات و دیدگاههای متناقض
این یافتههای اخیر که تحت عنوان «مراقب لحنتان باشید» منتشر شده، با نتایج یک مقاله تحقیقاتی دیگر که بیش از یک سال پیش چاپ شده بود، در تضاد است. آن تحقیق، شش چتبات را در چندین زبان تجزیه و تحلیل کرده و گزارش داده بود که بیادبی کیفیت پاسخها را کاهش میدهد و سوگیری، خطا یا حذف اطلاعات مفید را در پاسخهای ارائهشده توسط چتباتها به همراه دارد.
شایان ذکر است که کارشناسان پشت این تحقیق اخیر، ChatGPT را تنها برای نوع بسیار خاصی از کار آزمایش کردند که شامل ۲۵۰ تغییر از ۵۰ سوال چندگزینهای بود. بنابراین:
ممکن است نتایج مشابهی با دیگر چتباتها مانند جمینی (Gemini)، کلود (Claude) یا متا اِیآی (Meta AI) به دست نیاید.
آزمایشها روی مدلهای استدلالی GPT-4o از OpenAI انجام شدهاند، در حالی که آخرین نسخه عمومی ChatGPT بر پایه مدل جدید GPT-5 ساخته شده است.
طیف «بیادبی» و «ادب» بسیار گسترده است و کیفیت پاسخها بر اساس کلمات و زبان کاربر متفاوت خواهد بود. در نهایت، سوال بزرگتر این است که چگونه «بار احساسی یک عبارت» بر پاسخهای تولیدشده توسط یک چتبات هوش مصنوعی تاثیر میگذارد.












ارسال نظر